中国新能源汽车产业正站在一个微妙的十字路口。经历了十余年的“跑马圈地”,市场渗透率一路高歌猛进,行业却陷入了“增量不增收、增收不增利”的集体焦虑:产品迭代太快,供应链承压,价格战此起彼伏。曾经依靠放量驱动的粗放增长模式已然失效,单纯比拼销量和上新节奏的战场即将鸣金收兵。
新能源汽车的竞争重心正在“从规模扩张转向价值创造,从单点突破转向体系能力提升”。如果说上半场是用电力取代燃油的动力革命,那么下半场则是由算力定义、算法驱动、芯片奠基的智能化决战。汽车不再只是代步的钢铁躯壳,它正进化为能感知、决策甚至思考的轮式机器人。
PART 01
从“堆料”到“有效算力”的质变

如果将自动驾驶比作一场永不停歇的F1赛事,那么算力便是赛车的马力,算法则是车手的驾驶技术。海量传感器每秒产生的GB级数据洪流,只有依托强大的算力,才能实时处理转化为有效决策。
真正让智驾系统学会驾驶的,并不仅是车载芯片,还有幕后的服务器训练集群。通过来自测试车队和量产车回传的PB级真实路况数据,完成数据清洗、场景标注和数千亿次参数矩阵运算,让模型在海量视频中自主领悟驾驶逻辑。可以说,车载芯片是智驾的“考场”,而服务器才是真正的“驾校”。驶入考场的“考生”水平如何,不仅取决于驾校的训练强度,更取决于训练与推理之间的“教考匹配度”。云端训练出来表现优异的模型,一旦部署到车端,常常出现水土不服,实时推理延迟陡增、精度下降。这背后暴露出的,正是训练架构与推理架构之间的割裂。

正因如此,行业开始重新审视被忽略的有效算力。早期英伟达Orin-X芯片在适配Transformer大模型时,理论算力高达254 TOPS,实际有效算力利用率却远低于峰值。原因在于通用GPU架构并非为特定算法量身定制,大量的计算单元在跑Transformer时处于闲置或低效状态。
这一痛点,催生了两个方向的变革:一是车端推理芯片的“领域专用架构”转向,二是云端训练服务器的“算法-硬件协同设计”。在云端,现已有面向智驾训练的专用集群方案,服务器不再一味堆砌通用GPU,而是通过液冷散热、高速互联和分布式存储,针对主流智驾算法进行硬件层面的定制优化,大幅提升模型迭代效率,降低训练成本。在从“驾校”到“考场”的全链路优化竞赛中,真正的赢家不是堆砌数字的军备狂人,而是能让每一缕算力都转化为驾驶智慧的精益主义者。
PART 02
责任鸿沟下的算力远征
技术参数的狂飙最终服务于驾驶体验。目前我们正处于L2+(辅助驾驶)大规模普及的阶段。无论是高速导航辅助驾驶,还是城区道路的点到点通勤,车辆的“类人”驾驶能力已经让无数车主在长途跋涉中得以片刻喘息。然而,在迈向L3(有条件自动驾驶)的过程中,拦在面前的不仅是技术大山,更有一道难以逾越的“责任鸿沟”。
根据自动驾驶分级标准,L3是一个分水岭,在L2及以下,无论系统多么智能,事故都是驾驶员的责任;而在L4(完全自动驾驶)及以上,责任转移到了车企或系统方。唯独L3处于尴尬的中间态:在特定条件下由系统完全驾驶,但要求驾驶员在系统请求时必须随时接管。同济大学朱西产教授犀利指出,要求驾驶员“脱眼脱手但不能脱脑”,在现实中缺乏可操作性。这种责任归属的模糊,导致了行业内出现了剧烈的路线之争。

01
渐进派:L3是不可逾越的底座
以华为、长安、广汽、岚图等为代表的企业认为,L3是通往L4的必经之路。华为智能汽车解决方案BU CEO靳玉志直言,L4所需的“十倍人驾安全性”,必须通过L3阶段的海量数据验证和系统冗余设计来积累经验。
从训练侧来看,L3级别的系统对服务器的依赖远高于L2。L3要求模型具备极高的安全冗余和场景覆盖能力,这意味着训练阶段需要引入更多长尾场景数据,如极端天气、突发事故、异形障碍物等。这些数据需要经过服务器集群的高精度标注和强化学习训练,才能让模型在罕见但危险的场景中做出正确决策。
02
跨越派:大模型让我们跳过L3
而以小鹏、特斯拉、卓驭科技等为代表的另一派则认为,L3的商业价值极低,用户不愿为有限场景且权责模糊的功能买单,不如直接利用端到端大模型的技术红利,从L2直通L4。
在技术实现上,端到端大模型对云端推理服务器也提出了全新要求。传统的规则型模型可以在低算力芯片上运行,但大模型需要车载芯片具备更强的实时推理能力,同时云端需要部署高吞吐、低延迟的推理服务器集群,用于模型的持续验证和OTA前的仿真测试。以特斯拉的Dojo超算中心为例,其不仅用于训练,也承担着大规模仿真推理任务,这正是跨越派技术路线的底层支撑。
PART 03
算法革命与硬件的“自我进化”
跳过L3的底气来源于算法的范式革命。过去的自动驾驶依赖规则代码(If...Then...),无法穷尽长尾场景。而现在的端到端大模型,让车辆拥有了像人类一样的直觉和学习能力。它不再是机械地执行指令,而是通过学习海量驾驶视频,理解交通环境的逻辑。
端到端大模型的革命性,不仅体现在车端,更深刻地改变了云端训练与推理的硬件格局。传统服务器以CPU为核心,难以胜任千亿级参数的并行训练;如今AI智算中心已成为标配,通过超高速互联网络和分布式存储系统,共同完成单卡无法承受的超大模型训练任务。同时推理服务器也在快速进化,为了支撑数千万辆量产车同时调用云端模型进行实时验证或OTA前的仿真测试,推理服务器必须具备高吞吐、低延迟、弹性扩展的能力,这对硬件架构和算法压缩技术(如量化、剪枝、蒸馏)提出了更高要求。
在算法层面,分布式训练框架成为连接硬件与模型的“操作系统”。通过这些框架,开发者可以将一个庞大的模型切分到数千张GPU上并行计算,同时利用混合精度训练、梯度累积、通信优化等技术,逼近硬件的理论计算极限。可以说,云端训练算法的效率,直接决定了智驾模型的迭代速度与最终性能。这意味着,未来的汽车芯片不仅仅是硬件,它必须是为特定算法“量身定做”的硅基载体。而在云端,未来的AI服务器也将从通用计算设备,进化为面向智驾场景深度优化的专用训练与推理基础设施。
PART 04
算力向实,场景为王
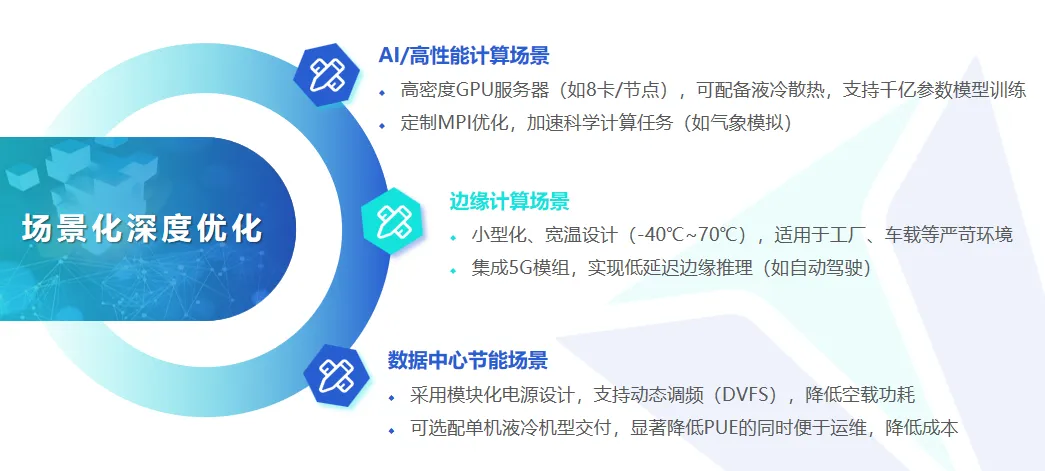
作为智能化变革的“幕后建造者”,极能核深知:每一段从容的变道、每一次精准的制动、每一回化险为夷的紧急避险,其源头都不是孤立的硬件参数,而是一条从数据采集→云端训练→仿真验证→车端推理的全链路算力闭环。在这个闭环中,服务器不再是传统意义上的IT设备,而是智驾系统的“第二大脑”——它承载着PB级数据的吞吐、千亿级参数的迭代、数万种虚拟场景的仿真推演。
基于这样的认知,极能核始终坚持一件事:为场景而生,为场景而造。 我们拒绝提供“一刀切”的通用服务器方案,而是深入理解千行百业智慧升级背后的底层计算特征,通过液冷散热、异构计算、高速互联、智能调度等技术创新,为每一个细分场景提供“开箱即用”的高效训练与推理基础设施,成为“让算力不再昂贵、让训练不再漫长、让推理不再延迟”的赋能者。